Manifest File
Manifest files are fundamental to Impact Framework and they serve multiple important purposes, including:
- They contain all the necessary configurations for Impact Framework
- They define your application architecture
- They hold your input data
- They are shareable, portable and human-readable
- They can be used as verifiable audits form your application
The manifest is a yaml file with a particular structure. It can be thought of as an executable audit because the file itself can be shared with others and re-executed to verify your environmental impact calculations.
It is a formal report detailing not just the end impact but all the assumptions, inputs, and plugins used in calculating the impact.
This is possible because all the configuration and data required to run Impact Framework is contained in the manifest file.
Anyone can download Impact Framework and execute a manifest file to verify the results.
Structure of a manifest file
Overview
Manifest files can be simple or very intricate, depending on the plugin pipeline you want to use and the complexity of your application. However, all manifest files conform to a basic structure that looks as follows:
name:
description:
tags:
initialize:
plugins:
<PLUGIN-NAME-HERE>:
method:
path:
tree:
children:
child:
pipeline:
observe:
regroup:
compute:
defaults:
inputs:
- timestamp: 2023-08-06T00:00
duration: 3600
Everything above the tree is collectively referred to as the context. The tree contains the input data and is structured according to the architecture of the application being examined, with individual components being nodes in the tree. Individual components can be grouped under parent nodes.
Context
Metadata
The global metadata includes the name, description, and tags that can be used to describe the nature of the manifest file. For example, you might name the file Carbon Jan 2024 or similar. A short description might briefly outline the scope of the manifest file, e.g. company x's carbon emissions due to web serves from Jab 24 - July 24. Tags is an object containing the string properties kind, complexity and category. It can be used to group manifest files (we do not explicitly use this field for anything currently).
Initialize
The initialize section is where you define which plugins will be used in your manifest file and provide the configuration for them. Below is sample for initialization:
initialize:
plugins:
<PLUGIN-NAME-HERE>:
method: <METHOD-NAME-HERE>
Where required values are:
method: the name of the function exported by the plugin.path: the path to the plugin code. For example, for a plugin from our standard library, this value would bebuiltin
There is also an optional config field that can be used to set config that is common to a plugin wherever it is invoked across the entire manifest file.
Impact Framework uses the initialize section to instantiate each plugin. A plugin cannot be invoked elsewhere in the manifest file unless it is included in this section.
There is also the option to provide a mapping to the plugin in the initialize block. Its purpose is to rename the arguments expected or returned from the plugin as part of the plugin's execution, avoiding the need to use additional plugins to rename parameters.
For example, your plugin might expect cpu/energy and your input data has the parameter cpu-energy returned from another plugin. Instead of using an additional plugin to rename the parameter and add a new one, you can use mapping to:
a) rename the output from the first plugin so that cpu/energy is returned instead of the default cpu-energy
b) instruct the second plugin to accept cpu-energy instead of the default cpu/energy
e.g.
initialize:
plugins:
sci:
kind: plugin
method: Sci
path: 'builtin'
config:
functional-unit: requests
mapping:
sci: if-sci
In the outputs, the sci value returned by the Sci plugin will be named if-sci.
You can also add information to the plugin's initialize section about parameter metadata if you wish to add or override the metadata hardcoded into the plugin. This is what will be reported by the explainer feature if you enable it. E.g.
plugins:
sum-carbon:
path: 'builtin'
method: Sum
config:
input-parameters:
- carbon-operational
- embodied-carbon
output-parameter: carbon
parameter-metadata:
inputs:
carbon-operational:
description: "carbon emitted due to an application's execution"
unit: 'gCO2eq'
aggregation-method:
time: sum
component: sum
embodied-carbon:
description: "carbon emitted during the production, distribution and disposal of a hardware component, scaled by the fraction of the component's lifespan being allocated to the application under investigation"
unit: 'gCO2eq'
aggregation-method:
time: sum
component: sum
Execution (auto-generated)
This section is auto generated by IF at runtime. You don't have to include this section in your manifest. The execution node contains all the necessary information to rebuild the environment, which can support debugging or verifying output files.
execution:
status: success
command: if-run --manifest examples/basic.yml
environment:
if-version: v0.3.2
os: ubuntu
os-version: 22.04.6
node-version: v21.4.0
date-time: 2023-12-12T00:00:00.000Z (UTC)
dependencies:
- '@babel/core@7.22.10'
- ...
error: 'InputValidationError: "duration" parameter is required. Error code: invalid_type'. ## appears when execution failed
- status: execution state:
success(indicating that IF successfully executed this manifest) orfail(indicating that IF encountered a problem that halted execution). - command: exact command which was used to run the framework to execute this manifest (it may include full path to tools in place of aliases such as
run) - environment: information about the environment the manifest was executed in, including the local operating system, Node.js version, time, and dependencies.
- error: this field only appears if execution failed. The error message returned by IF is captured here.
Explain
This section is autogenerated at runtime. It is a list of all the parameter metadata that IF can scrape from your plugin instances. It looks as follows:
explain:
sci-plugin:
inputs:
carbon:
unit: gCO2eq
description: >-
total carbon emissions attributed to an application's usage as the sum
of embodied and operational carbon
aggregation-method:
time: sum
component: sum
requests:
unit: requests
description: number of requests made to application in the given timestep
aggregation-method:
time: sum
component: sum
outputs:
sci:
unit: gCO2eq/request
description: >-
software carbon intensity expressed as a rate of carbon emission per
request
aggregation-method:
time: sum
component: sum
Tree
The tree section of a manifest file defines the topology of all the components being measured. The shape of the tree defines the grouping of components. It describes the architecture of the application being studied and contains all the usage observations for each component. The tree has individual components such as leaves, intermediate nodes representing groupings, and the top level is the root.
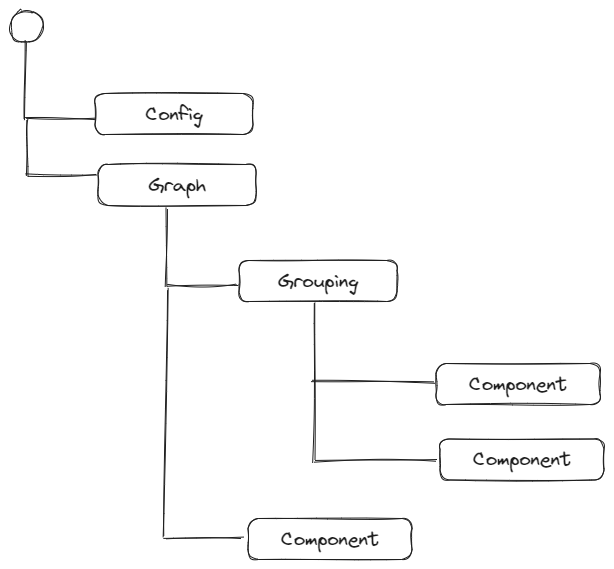
For example, a web application could be organized as follows:
tree:
children:
front-end:
children:
build-pipeline:
children:
vercel:
github-pages:
backend-database:
children:
server1:
server2:
server3:
front-end:
networking:
This example has a relatively straightforward structure with a maximum of 3 levels of nesting. You can continue to nest components to any depth.
Each component has some configuration, some input data, and a plugin pipeline.
pipeline: a list of plugins that should be executed for a specific component. This is broken down into three subsections representing distinct phases of execution that can be triggered independently using command line flags. These subsections are:observe: the plugins that generate input dataregroup: configuration for regrouping input data by given keyscompute: the plugins that operate over input data and generate output data
defaults: fallback values that IF defaults to if they are not present in an input observation.inputs: an array ofobservationdata, with eachobservationcontaining usage data for a given timestep.
If a component does not include its own pipeline or defaults values, they are inherited from the closest parent.
Here's an example of a moderately complex tree:
tree:
children:
child-0:
children:
child-0-1:
pipeline:
observe:
regroup:
compute:
- sum
defaults:
inputs:
- timestamp: 2023-07-06T00:00
duration: 10
cpu-util: 50
energy-network: 0.000811
outputs:
- timestamp: 2023-07-06T00:00
duration: 10
cpu-util: 50
energy-network: 0.000811
energy: 0.000811
child-0-2:
children:
child-0-2-1:
pipeline:
observe:
regroup:
compute:
- sum
defaults:
inputs:
- timestamp: 2023-07-06T00:00
duration: 10
cpu-util: 50
energy-network: 0.000811
outputs:
- timestamp: 2023-07-06T00:00
duration: 10
cpu-util: 50
energy-network: 0.000811
energy: 0.000811
Defaults
Defaults are fallback values that are only used if a given value is missing in the inputs array. For example, if you have a value that could feasibly be missing in a given timestep, perhaps because your plugin relies on a third party API that can fail, you can provide a value in defaults that can be used as a fallback value.
The values in defaults are applied to every timestep where the given value is missing. This means that as well as acting as a fallback defaults can be used as a convenience tool for efficiently adding a constant value to every timestep in your inputs array.
Inputs
Every component includes an inputs field that gets read into plugins as an array. inputs are divided into observations, each having a timestamp and a duration. Every observation refers to an element in inputs representing some snapshot in time.
Each plugin takes the inputs array and applies some calculation or transformation to each observation in the array.
Observations can include any type of data, including human judgment, assumptions, other plugins, APIs, survey data or telemetry.
The separation of timestamps in the inputs array determines the temporal granularity of your impact calculations. The more frequent your observations, the more accurate your impact assessment.
Creating input data
The plugins in the observe part of the pipeline generate input data. The manifest file should not have input data when the observe phase is executed. Plugins in this phase only generate input data, they can never generate output data. If you run the observe phase on its own (by running if-run --observe) then your manifest will be returned populated with input data according to the plugins you included in your observe pipeline.
Regrouping a manifest file
The second phase of manifest execution is regroup. This reorganizes existing input data into a new structure using keys provided in the regroup config in the manifest. For example, a manifest with the following tree:
tree:
children:
my-app:
pipeline:
observe:
regroup:
- cloud/instance-type
- cloud/region
compute:
children:
inputs:
- timestamp: 2023-07-06T00:00
duration: 300
cloud/instance-type: A1
cloud/region: uk-west
cpu/utilization: 99
- timestamp: 2023-07-06T05:00
duration: 300
cloud/instance-type: A1
cloud/region: uk-west
cpu/utilization: 23
- timestamp: 2023-07-06T10:00
duration: 300
cloud/instance-type: A1
cloud/region: uk-west
cpu/utilization: 12
- timestamp: 2023-07-06T00:00
duration: 300
cloud/instance-type: B1
cloud/region: uk-west
cpu/utilization: 11
- timestamp: 2023-07-06T05:00
duration: 300
cloud/instance-type: B1
cloud/region: uk-west
cpu/utilization: 67
- timestamp: 2023-07-06T10:00
duration: 300
cloud/instance-type: B1
cloud/region: uk-west
cpu/utilization: 1
- timestamp: 2023-07-06T00:00
duration: 300
cloud/instance-type: A1
cloud/region: uk-east
cpu/utilization: 9
- timestamp: 2023-07-06T05:00
duration: 300
cloud/instance-type: A1
cloud/region: uk-east
cpu/utilization: 23
- timestamp: 2023-07-06T10:00
duration: 300
cloud/instance-type: A1
cloud/region: uk-east
cpu/utilization: 12
- timestamp: 2023-07-06T00:00
duration: 300
cloud/instance-type: B1
cloud/region: uk-east
cpu/utilization: 11
- timestamp: 2023-07-06T05:00
duration: 300
cloud/instance-type: B1
cloud/region: uk-east
cpu/utilization: 67
- timestamp: 2023-07-06T10:00
duration: 300
cloud/instance-type: B1
cloud/region: uk-east
cpu/utilization: 1
generates the following output when if-run --regroup is executed:
tree:
children:
my-app:
pipeline:
observe:
regroup:
- cloud/instance-type
- cloud/region
compute:
children:
A1:
children:
uk-west:
inputs:
- timestamp: 2023-07-06T00:00
duration: 300
cloud/instance-type: A1
cloud/region: uk-west
cpu/utilization: 99
- timestamp: 2023-07-06T05:00
duration: 300
cloud/instance-type: A1
cloud/region: uk-west
cpu/utilization: 23
- timestamp: 2023-07-06T10:00
duration: 300
cloud/instance-type: A1
cloud/region: uk-west
cpu/utilization: 12
uk-east:
inputs:
- timestamp: 2023-07-06T00:00
duration: 300
cloud/instance-type: A1
cloud/region: uk-east
cpu/utilization: 9
- timestamp: 2023-07-06T05:00
duration: 300
cloud/instance-type: A1
cloud/region: uk-east
cpu/utilization: 23
- timestamp: 2023-07-06T10:00
duration: 300
cloud/instance-type: A1
cloud/region: uk-east
cpu/utilization: 12
B1:
children:
uk-west:
inputs:
- timestamp: 2023-07-06T00:00
duration: 300
cloud/instance-type: B1
cloud/region: uk-west
cpu/utilization: 11
- timestamp: 2023-07-06T05:00
duration: 300
cloud/instance-type: B1
cloud/region: uk-west
cpu/utilization: 67
- timestamp: 2023-07-06T10:00
duration: 300
cloud/instance-type: B1
cloud/region: uk-west
cpu/utilization: 1
uk-east:
inputs:
- timestamp: 2023-07-06T00:00
duration: 300
cloud/instance-type: B1
cloud/region: uk-east
cpu/utilization: 11
- timestamp: 2023-07-06T05:00
duration: 300
cloud/instance-type: B1
cloud/region: uk-east
cpu/utilization: 67
- timestamp: 2023-07-06T10:00
duration: 300
cloud/instance-type: B1
cloud/region: uk-east
cpu/utilization: 1
Computing a manifest file
Impact Framework computes manifest files. For each component in the tree, the inputs array is passed to each plugin in the compute pipeline in sequence.
In order for the compute phase to execute correctly, the manifest needs to have input data available.
Each plugin enriches the inputs array in some specific way, typically by adding a new key-value pair to each observation in the array. For example, the teads-curve plugin takes in CPU utilization expressed as a percentage as an input and appends cpu/energy expressed in kWh. cpu/energy is then available to be passed as an input to, for example, the sci-e plugin.
This implies a sequence of plugins where the inputs for some plugins must either be present in the original manifest file or be outputs of the preceding plugins in the pipeline.
There are also plugins and built-in features that can synchronize time series of observations across an entire tree and aggregate data across time or across components.
Running combinations of phases
It is possible to run each phase of the execution individually, or together. You can choose to only run the observe, regroup or compute phases of the manifest execution. This saves you from having to re-execute entire manifests every time you want to tweak something, making it a greener way to use IF.
if-run executes all the phases together, including observe, regroup and compute. It generates yaml output data. However, you can run individual phases by passing --observe, --regroup or --compute flags on the command line. For example, to run only the compute phase:
if-run -m <manifest> --compute
Maybe you only want to generate a static file that contains input data but don't want to run the full compute pipeline right now. You can run with --observe:
if-run <manifest> --observe
You can also combine the command, e.g. if you have a file with inputs and you want to run regroup and compute but not observe:
if-run -m <manifest> --regroup --compute
Outputs
When Impact Framework computes a manifest file, it appends new data to the manifest file and the final result is an enriched manifest that includes all the configuration and contextual data, the input data, and the results of executing each plugin. This means the output file is completely auditable - the original manifest file can be recovered simply by deleting the outputs and execution sections of the output file.
IF generates yaml output data. Any other output formats have to be generated by separate exhaust scripts that take IF's yaml output as their input.
Here's an example output file:
name: sum
description: successful path
tags: null
initialize:
plugins:
sum:
path: builtin
method: Sum
config:
input-parameters:
- cpu/energy
- network/energy
output-parameter: energy
execution:
command: >-
/home/user/.npm/_npx/1bf7c3c15bf47d04/node_modules/.bin/ts-node
/home/user/Code/if/src/index.ts -m
/home/user/Code/if/manifests/plugins/sum/success.yml
environment:
if-version: 0.3.3-beta.0
os: linux
os-version: 5.15.0-105-generic
node-version: 21.4.0
date-time: 2024-05-31T09:18:48.895Z (UTC)
dependencies:
- '@babel/core@7.22.10'
- '@babel/preset-typescript@7.23.3'
- '@commitlint/cli@18.6.0'
- '@commitlint/config-conventional@18.6.0'
- '@jest/globals@29.7.0'
- '@types/jest@29.5.8'
- '@types/js-yaml@4.0.9'
- '@types/luxon@3.4.2'
- '@types/node@20.9.0'
- csv-stringify@6.4.6
- fixpack@4.0.0
- gts@5.2.0
- husky@8.0.3
- jest@29.7.0
- js-yaml@4.1.0
- lint-staged@15.2.2
- luxon@3.4.4
- release-it@16.3.0
- rimraf@5.0.5
- ts-command-line-args@2.5.1
- ts-jest@29.1.1
- typescript-cubic-spline@1.0.1
- typescript@5.2.2
- winston@3.11.0
- zod@3.22.4
status: success
tree:
children:
child:
pipeline:
observe:
regroup:
compute:
- sum
inputs:
- timestamp: 2023-08-06T00:00
duration: 3600
cpu/energy: 0.001
network/energy: 0.001
outputs:
- timestamp: 2023-08-06T00:00
duration: 3600
cpu/energy: 0.001
network/energy: 0.001
energy: 0.002